Agent Evaluation 🔒
This template creates an agent run review Interface for evaluating multi-step agent traces — reasoning, tool calls, subagents, artifacts, and errors — produced by an LLM agent against a user request.
Annotators read through the trace step-by-step, rate individual steps as correct, partial, or incorrect, assign an overall verdict (good / mixed / bad), score the run against a configurable rubric, tag failure modes, and write a free-text critique that AI-quality teams use to grade agent performance and inform agent-development changes.
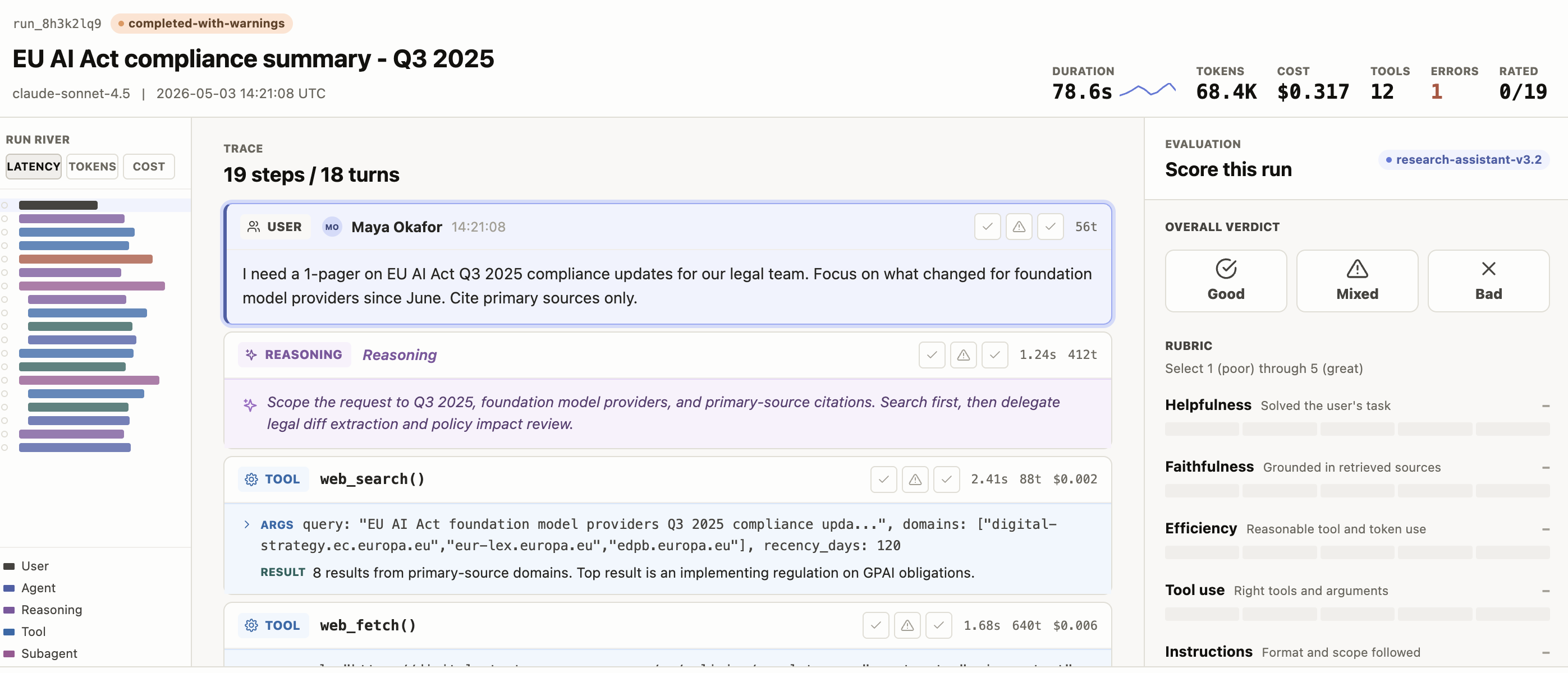
The example Interface includes:
- Run header with the run ID, agent and model names, status, start time, and a KPI strip for duration, tokens, cost, tool calls, errors, and rated-step progress.
- Run river minimap — a left rail listing every step in order, colored by kind, sized by the selected metric (
latency,tokens, orcost), with click-to-seek scrolling. - Trace canvas is the main reading column rendering steps by kind (user, reasoning, tool_call, error, subagent, artifact, agent) with expandable subagent children and inline per-step rating pills.
- Scoring panel with overall verdict, configurable rubric rows, per-step rating tallies, failure-mode tag chips, and a critique textarea — each saved as its own annotation result.
Enterprise
Interfaces can only be used in Label Studio Enterprise and Starter Cloud.
note
To use template Interfaces, you must first create an editable copy of the Interface. From Interfaces >Templates, select the overflow menu next to the template you want to use and click Duplicate.
Interface UI
The Interface is divided into three columns plus a sticky run header.
Run header
A single sticky bar with the run identity on the left and a KPI strip on the right.
- The left block shows the run ID, a status badge (
completed,completed-with-warnings, orfailed), the run name, the model, and the start timestamp. Once a verdict is set, aVerdict: <label>badge appears next to the status. - The right block shows KPIs for Duration, Tokens, Cost, Tools, Errors, and a Rated counter (
<scored_steps>/<total_steps>). Each KPI only renders if the corresponding field exists on the run.

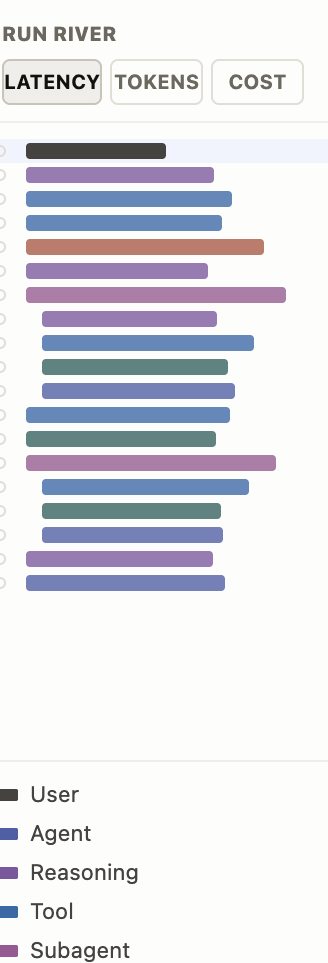
Run river minimap
A vertical minimap of every step. Each row is colored by step kind and sized by the selected metric.
- The Latency / Tokens / Cost tabs at the top change which metric drives the bar width.
- Indentation reflects subagent nesting; subagent children sit underneath their parent.
- A score dot to the left of each bar reflects the step’s per-step rating.
- A color legend at the bottom maps each step kind (User, Agent, Reasoning, Tool, Subagent, Artifact, Error) to its swatch.
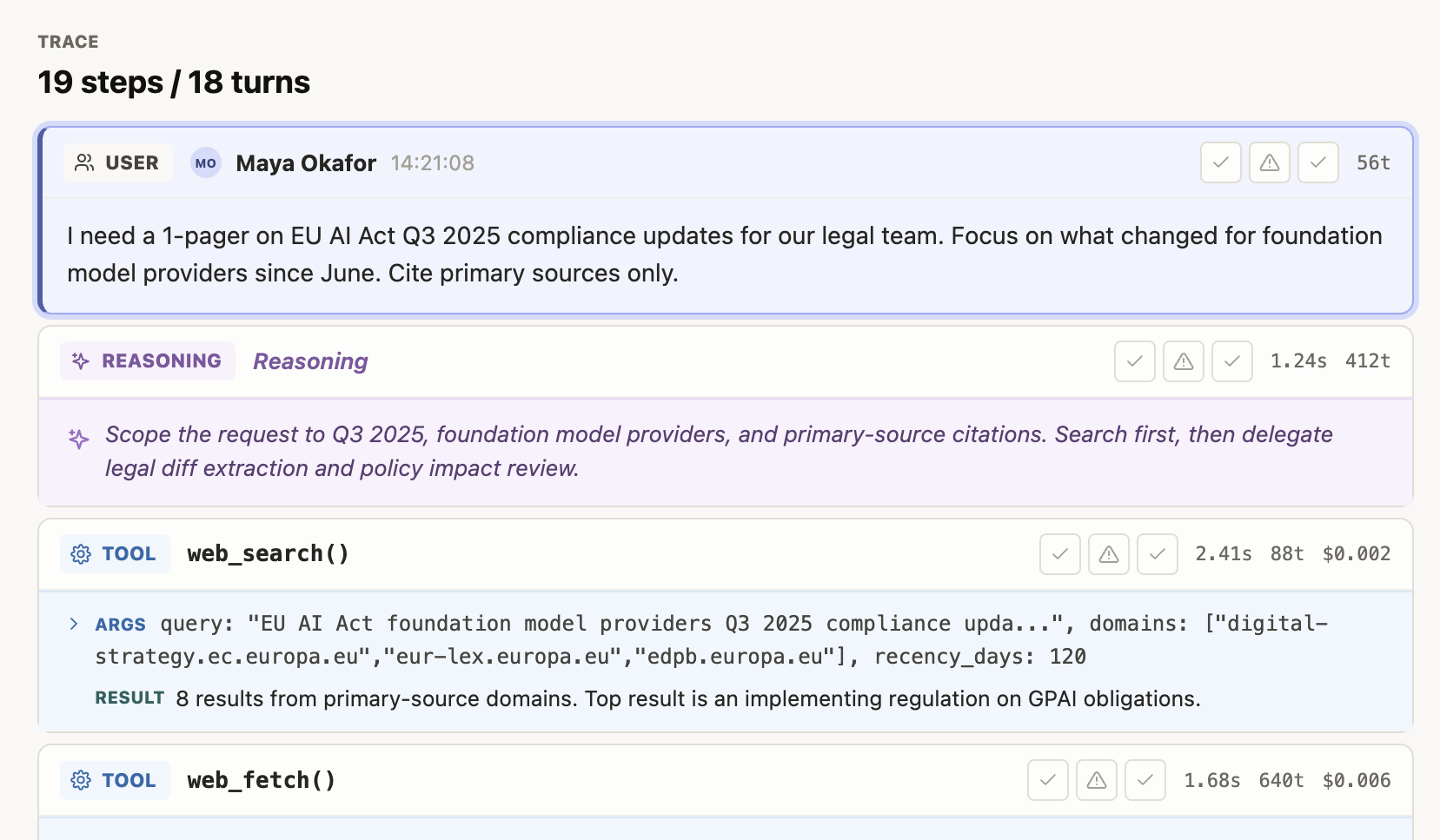
Trace canvas
The main reading column. Each step renders as a card with a kind icon, title, time, duration, token/cost metadata, and a rating pill row.
- The rating pills correspond to
stepRatingLabels—correct,partial,incorrectby default. Clicking a pill rates the step; clicking the active pill clears the rating. - Subagent steps are expandable — toggle to reveal nested child steps (reasoning, tool calls, artifacts, agent messages).
- Tool calls show their
argsinline and a preview of the returnedresult. - Errors render with their error code and message.
- The Show reasoning param hides reasoning steps when set to
false, which is useful when reviewing only externally-visible behavior.
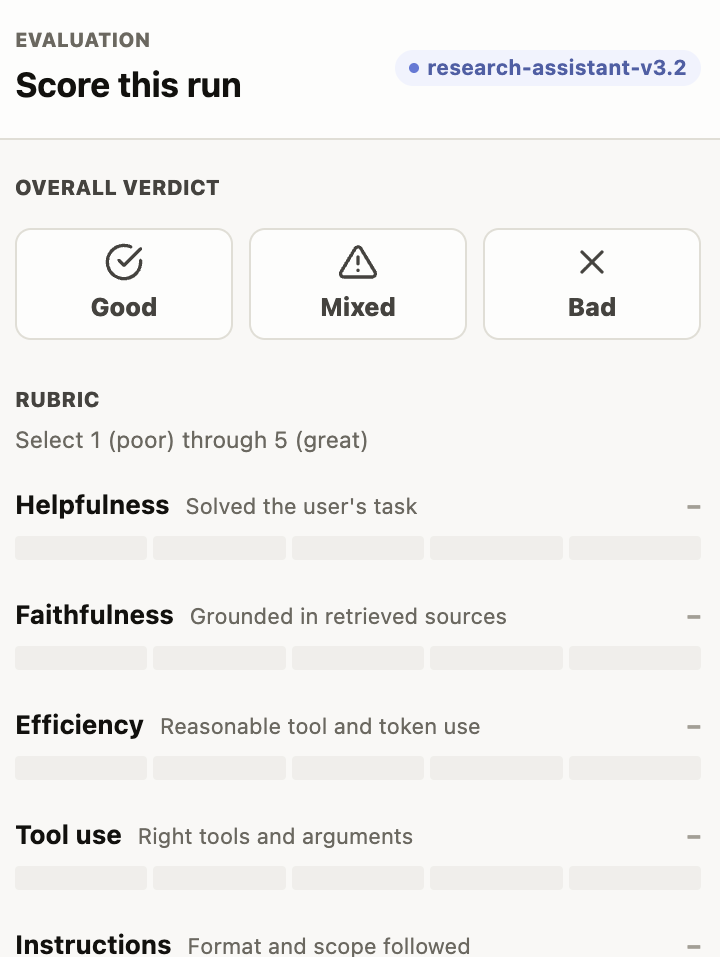
Scoring panel
A right-side rail with five sections, each persisted as its own annotation result so reviewers can mix-and-match what they fill in:
- Overall verdict — one button per entry in
verdictLabels. Clicking again clears the verdict. - Rubric — one 1-5 row per entry in
rubricItems. Each scored dimension becomes a separaterubricresult. - Per-step ratings — a read-only tally of how many steps received each rating, fed by the pills in the trace canvas.
- Failure modes — toggleable tag chips from
failureModeLabels. - Critique — a free-text textarea that saves as a
critiqueannotation result.
React code
The full Screen.jsx source is roughly 2,000 lines, so the snippets below highlight the parts you are most likely to customize:
- The params you wire to your task data
- The default label sets (verdicts, step ratings, failure modes, rubric items)
- The step kind metadata
- The result shape it writes back to Label Studio
Interface params
Set or rename a param on the Interface config to point at a different task field, change the default density, hide reasoning steps, or switch the minimap metric. The defaults mirror the example input below.
const paramsSchema = {
type: "object",
properties: {
runField: {
type: "dataField",
title: "Run field",
default: "run",
description: "Task data field containing the agent run object",
},
verdictLabels: { type: "labels", title: "Verdict labels", default: DEFAULT_VERDICT_LABELS },
stepRatingLabels: { type: "labels", title: "Step rating labels", default: DEFAULT_STEP_RATING_LABELS },
failureModeLabels: { type: "labels", title: "Failure mode labels", default: DEFAULT_FAILURE_MODE_LABELS },
rubricItems: {
type: "array",
title: "Rubric items",
default: DEFAULT_RUBRIC_ITEMS,
description: "Rubric dimensions shown in the scoring panel",
},
density: { type: "string", title: "Density", enum: ["compact", "comfortable"], default: "comfortable" },
showReasoning: { type: "boolean", title: "Show reasoning", default: true },
minimapMode: { type: "string", title: "River metric", enum: ["latency", "tokens", "cost"], default: "latency" },
},
};Default label sets
These four constants drive the verdict buttons, step rating pills, failure-mode chips, and rubric rows. Edit them in place to rename or recolor a label, drop one, or add a new entry.
const DEFAULT_VERDICT_LABELS = [
{ name: "good", color: "#22625d" },
{ name: "mixed", color: "#664228" },
{ name: "bad", color: "#b3523d" },
];
const DEFAULT_STEP_RATING_LABELS = [
{ name: "correct", color: "#34988d" },
{ name: "partial", color: "#e69559" },
{ name: "incorrect", color: "#e6694e" },
];
const DEFAULT_FAILURE_MODE_LABELS = [
{ name: "hallucination", color: "#e6694e" },
{ name: "missing_citation", color: "#e69559" },
{ name: "stale_data", color: "#e69559" },
{ name: "wrong_tool", color: "#e69559" },
{ name: "verbose", color: "#a49f95" },
{ name: "incomplete", color: "#e69559" },
{ name: "off_topic", color: "#a49f95" },
{ name: "good_recovery", color: "#34988d" },
];
const DEFAULT_RUBRIC_ITEMS = [
{ id: "helpfulness", label: "Helpfulness", desc: "Solved the user's task" },
{ id: "faithfulness", label: "Faithfulness", desc: "Grounded in retrieved sources" },
{ id: "efficiency", label: "Efficiency", desc: "Reasonable tool and token use" },
{ id: "tool_use", label: "Tool use", desc: "Right tools and arguments" },
{ id: "instruction_following", label: "Instructions", desc: "Format and scope followed" },
];Step kind metadata
Each step has a kind. stepMeta returns the color, background, label, and icon used in the trace canvas and the river minimap. Add a new kind (for example, tool_result) by extending this map.
function stepMeta(kind) {
return (
{
user: { color: "var(--color-sand-700)", bg: "var(--color-sand-100)", label: "User", icon: "people" },
agent: { color: "var(--color-grape-700)", bg: "var(--color-grape-000)", label: "Agent", icon: "spark" },
reasoning: { color: "var(--color-fig-700)", bg: "var(--color-fig-000)", label: "Reasoning", icon: "sparkle" },
tool_call: { color: "var(--color-blueberry-700)", bg: "var(--color-blueberry-000)", label: "Tool", icon: "settings" },
subagent: { color: "var(--color-plum-700)", bg: "var(--color-plum-000)", label: "Subagent", icon: "models" },
artifact: { color: "var(--color-kale-700)", bg: "var(--color-kale-000)", label: "Artifact", icon: "folder" },
error: { color: "var(--color-persimmon-700)", bg: "var(--color-persimmon-000)", label: "Error", icon: "warning" },
}[kind] || /* fallback to a neutral "Step" entry */
);
}Result shape
getResults builds the annotation that Label Studio persists. Unlike the other Interfaces, this one emits up to five independent results — one per scoring section — all attached to a single run object. Each result is only emitted if the reviewer actually filled in that section, so partial annotations save cleanly.
function getResults(regions) {
// Emits up to five independent results, all with to_name: "run":
//
// 1. step_classification (choices) - one combined result for all per-step pills
// value: { choices: [unique_ratings...], step_scores: { [stepId]: rating }, run_id }
//
// 2. verdict (choices) - the overall verdict
// value: { choices: [verdict], verdict, run_id }
//
// 3. rubric (number) - one per scored rubric dimension
// value: { number: score, rubric_id, rubric_label, run_id }
//
// 4. failure_modes (choices) - the selected failure-mode tags
// value: { choices: [tag...], failure_tags: [tag...], run_id }
//
// 5. critique (textarea) - the free-text notes
// value: { text: [notes], notes, run_id }
}Example input
The Interface expects a task data object with a run field (or whichever field name you configure via runField). Each entry in run.steps has a kind (user, reasoning, tool_call, subagent, artifact, error, or agent) plus kind-specific fields. Subagent steps can carry a children array of nested steps.
Click to expand
{
"data": {
"run": {
"id": "run_8h3k2lq9",
"name": "EU AI Act compliance summary - Q3 2025",
"agent": "research-assistant-v3.2",
"model": "claude-sonnet-4.5",
"status": "completed-with-warnings",
"startedAt": "2026-05-03T14:21:08Z",
"duration": 78.6,
"totalTokens": 68420,
"totalCost": 0.317,
"turns": 18,
"toolCalls": 12,
"subagents": 2,
"errors": 1,
"retries": 2,
"steps": [
{
"id": "s1",
"kind": "user",
"author": "Maya Okafor",
"time": "14:21:08",
"content": "I need a 1-pager on EU AI Act Q3 2025 compliance updates for our legal team. Focus on what changed for foundation model providers since June. Cite primary sources only.",
"tokens": 56
},
{
"id": "s2",
"kind": "reasoning",
"time": "14:21:09",
"durationMs": 1240,
"tokens": 412,
"summary": "Scope the request to Q3 2025, foundation model providers, and primary-source citations. Search first, then delegate legal diff extraction and policy impact review."
},
{
"id": "s3",
"kind": "tool_call",
"tool": "web_search",
"time": "14:21:10",
"durationMs": 2410,
"tokens": 88,
"cost": 0.002,
"args": {
"query": "EU AI Act foundation model providers Q3 2025 compliance updates",
"domains": ["digital-strategy.ec.europa.eu", "eur-lex.europa.eu", "edpb.europa.eu"],
"recency_days": 120
},
"result": {
"ok": true,
"results": 8,
"preview": "8 results from primary-source domains. Top result is an implementing regulation on GPAI obligations."
}
},
{
"id": "s5",
"kind": "error",
"tool": "web_fetch",
"time": "14:21:15",
"durationMs": 8200,
"args": { "url": "https://ec.europa.eu/digital-strategy/news/ai-act-q3-update", "timeout_ms": 8000, "retry": 1 },
"error": { "code": "TIMEOUT", "message": "Upstream timed out after 8000ms." },
"retried": true
},
{
"id": "s7",
"kind": "subagent",
"name": "legal-analysis",
"role": "Extract structured changes from primary sources",
"model": "claude-sonnet-4.5",
"time": "14:21:27",
"durationMs": 18740,
"tokens": 14820,
"cost": 0.094,
"summary": "Returned article-level changes with verified citations and a structured obligation table.",
"children": [
{
"id": "s7.2",
"kind": "tool_call",
"tool": "extract_legal_diff",
"args": { "document_id": "reg_impl_2025_1847", "baseline": "reg_2024_1689", "sections": ["Article 53", "Article 55", "Annex XI"] },
"result": { "ok": true, "changes": 7, "preview": "7 article-level changes; 4 affect GPAI providers." }
},
{
"id": "s7.3",
"kind": "artifact",
"title": "Source-backed obligations table",
"artifactType": "markdown",
"preview": "| Obligation | Source | Q3 change |\n| --- | --- | --- |\n| Technical documentation | Article 53 | Template fields clarified |"
}
]
},
{
"id": "s9",
"kind": "artifact",
"title": "Citation matrix draft",
"artifactType": "markdown",
"preview": "| Claim | Citation | Status |\n| --- | --- | --- |\n| Documentation template clarified | EUR-Lex reg_impl_2025_1847 | verified |\n| Enforcement examples updated | Commission news page | needs review |"
},
{
"id": "s12",
"kind": "agent",
"time": "14:22:27",
"durationMs": 1840,
"tokens": 610,
"content": "Draft complete: a 1-page Q3 2025 EU AI Act update with three provider obligations, a citation matrix, and a reviewer note for the timed-out Commission page."
}
// ... more steps
]
}
}
}Example output
The saved annotation contains up to five independent results, all attached to the same run object. Each section in the scoring panel produces its own result, and any section the reviewer leaves blank is simply omitted.
For example (partial JSON):
{
"result": [
{
"id": "agent-evaluation-run_8h3k2lq9-step-classification",
"from_name": "step_classification",
"to_name": "run",
"type": "choices",
"value": {
"choices": ["correct", "partial", "incorrect"],
"step_scores": {
"s2": "correct",
"s3": "correct",
"s5": "incorrect",
"s7": "partial",
"s9": "correct",
"s12": "correct"
},
"run_id": "run_8h3k2lq9"
}
},
{
"id": "agent-evaluation-run_8h3k2lq9-verdict",
"from_name": "verdict",
"to_name": "run",
"type": "choices",
"value": {
"choices": ["mixed"],
"verdict": "mixed",
"run_id": "run_8h3k2lq9"
}
},
{
"id": "agent-evaluation-run_8h3k2lq9-rubric-faithfulness",
"from_name": "rubric",
"to_name": "run",
"type": "number",
"value": {
"number": 4,
"rubric_id": "faithfulness",
"rubric_label": "Faithfulness",
"run_id": "run_8h3k2lq9"
}
},
{
"id": "agent-evaluation-run_8h3k2lq9-rubric-tool_use",
"from_name": "rubric",
"to_name": "run",
"type": "number",
"value": {
"number": 3,
"rubric_id": "tool_use",
"rubric_label": "Tool use",
"run_id": "run_8h3k2lq9"
}
},
{
"id": "agent-evaluation-run_8h3k2lq9-failure-modes",
"from_name": "failure_modes",
"to_name": "run",
"type": "choices",
"value": {
"choices": ["missing_citation", "good_recovery"],
"failure_tags": ["missing_citation", "good_recovery"],
"run_id": "run_8h3k2lq9"
}
},
{
"id": "agent-evaluation-run_8h3k2lq9-critique",
"from_name": "critique",
"to_name": "run",
"type": "textarea",
"value": {
"text": ["Strong primary-source grounding for most claims, but one Commission news citation is still unresolved after the web_fetch timeout. Good recovery via EUR-Lex; faithfulness penalized for the unresolved citation."],
"notes": "Strong primary-source grounding for most claims, but one Commission news citation is still unresolved after the web_fetch timeout. Good recovery via EUR-Lex; faithfulness penalized for the unresolved citation.",
"run_id": "run_8h3k2lq9"
}
}
]
}